Local Inference With Llama Cpp And Turboquant Information Center
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.
Background on Local Inference With Llama Cpp And Turboquant
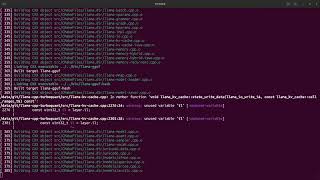
This tutorial provides instructions for building and running In this video, we're going to learn how to do naive/basic RAG (Retrieval Augmented Generation) with Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Here's the one change that took mine from ~120 tok/s to 1200+ without a new GPU. TryHackMe just launched Cyber Security 101 ... Best Deals on Amazon: MY TOP PICKS + INSIDER DISCOUNTS: I ... This video compares the K-V cache memory savings with
MTP (Multi-Token prediction) is not a new idea, but it is *finally* supported in the beloved In this video I take a dive into NVidia's NVFP4 quantization, and compare it against established GGUF Q4_K_M models. Best Deals on Amazon: MY TOP PICKS + INSIDER DISCOUNTS: I ... Unlock the future of AI! Discover a game-changing Python coding opportunity to revolutionize AI agents and Generative AI.
Main Features

Explore the main sources for Local Inference With Llama Cpp And Turboquant.
History

Stay updated on Local Inference With Llama Cpp And Turboquant's latest milestones.
Featured Video Reports & Highlights
Below is a handpicked selection of video coverage, expert reports, and highlights regarding Local Inference With Llama Cpp And Turboquant from verified contributors.
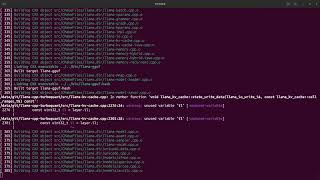
Local Inference with Llama.cpp and TurboQuant

Local AI just leveled up... Llama.cpp vs Ollama

Local RAG with llama.cpp

Ultimate Guide Local AI Setup (Qwen3.6 + LlamaC++ + TurboQuant)
Deep Dive
Data is compiled from public records and verified media reports.
Last Updated: May 26, 2026
Final Thoughts

For 2026, Local Inference With Llama Cpp And Turboquant remains one of the most searched-for profiles. Check back for the newest reports.
Disclaimer:


















