Slimqwen Optimizing Large Moe Model Compression Through Pruning And Distillation Information Center
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.
Introduction of Slimqwen Optimizing Large Moe Model Compression Through Pruning And Distillation

In this AI Research Roundup episode, Alex discusses the paper: ' Try Voice Writer - speak your thoughts and let AI handle the grammar: Four techniques to Ever wonder how powerful AI models can run on your smartphone? The secret is Want your team maximizing Claude? I run 1:1 and team AI workshops for companies doing $1M+ per year: ... This lecture (by Vijay Viswanathan) for CMU CS 11-711, Advanced NLP (Fall 2024) covers: * In this highly visual guide, we explore the architecture of a Mixture of Experts in
This lecture (by Vijay Viswanathan) for CMU CS 11-711, Advanced NLP (Spring 2024) covers: *
Important Facts

Explore the primary sources for Slimqwen Optimizing Large Moe Model Compression Through Pruning And Distillation.
History
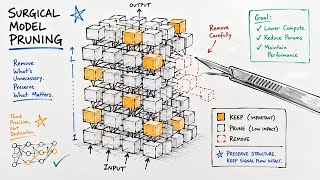
Stay updated on Slimqwen Optimizing Large Moe Model Compression Through Pruning And Distillation's newest achievements.
Featured Video Reports & Highlights
Below is a handpicked selection of video coverage, expert reports, and highlights regarding Slimqwen Optimizing Large Moe Model Compression Through Pruning And Distillation from verified contributors.
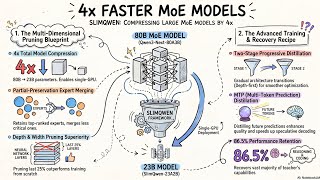
SlimQwen: Optimizing Large MoE Model Compression Through Pruning and Distillation

SlimQwen: Efficient MoE Pruning and Distillation
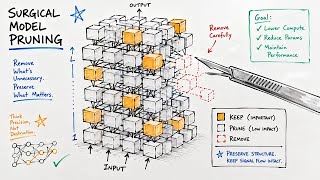
SlimQwen: Compressing Giant Mixture-of-Experts Models Without Losing Their Edge
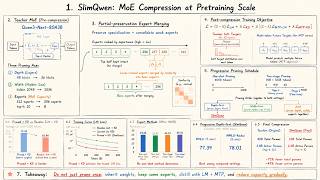
SlimQwen in 1 Minute: How to Compress Huge MoE Models
Detailed Analysis
Data is compiled from public records and verified media reports.
Last Updated: May 26, 2026
Future Outlook

For 2026, Slimqwen Optimizing Large Moe Model Compression Through Pruning And Distillation remains one of the most searched-for profiles. Check back for the latest updates.
Disclaimer:



















