The Kv Cache Memory Usage In Transformers Information Center
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.
Overview of The Kv Cache Memory Usage In Transformers

Try Voice Writer - speak your thoughts and let AI handle the grammar: In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses This is a single lecture from a course. If you you like the material and want more context (e.g., the lectures that came before), check ... Don't like the Sound Effect?:* *LLM Training Playlist:* ... Every time you chat with a large language model, a silent computational storm rages inside the GPU. In autoregressive decoding ... Large Language Models are powerful, but they have a massive bottleneck:
Ready to bring your language model up to state-of-the-art speeds? In this hands-on tutorial, you'll build a Ready to become a certified watsonx Generative AI Engineer? Register now and Lex Fridman Podcast full episode: Thank you for listening ❤ our ... Ever wonder how even the largest frontier LLMs are able to respond so quickly in conversations? In this short video, Harrison Chu ... Chapters: 00:00 Welcome to Pop Goes the Stack 00:18 GPUs aren't the inference bottleneck— In this video I am explaining the one trick that makes token generation on modern LLMs 10-100 times faster:
Key Details

Explore the main sources for The Kv Cache Memory Usage In Transformers.
大家好欢迎来到AI开发者的频道 今天呢我们来了解一下 大语言模型推理中 的一个非常重要的技术 也就是 In this AI Research Roundup episode, Alex discusses the paper: 'Self-Pruned Key-Value Attention: Learning When to Write by ... Have you ever wondered how massive language models like DeepSeek-R1 and Qwen3 handle complex math problems without ...
Latest News

Stay updated on The Kv Cache Memory Usage In Transformers's newest achievements.
Featured Video Reports & Highlights
Below is a handpicked selection of video coverage, expert reports, and highlights regarding The Kv Cache Memory Usage In Transformers from verified contributors.
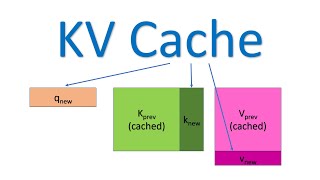
The KV Cache: Memory Usage in Transformers

KV Cache: The Trick That Makes LLMs Faster
![KV Caching: Speeding up LLM Inference [Lecture]](https://ytimg.googleusercontent.com/vi/_quDGLpNols/mqdefault.jpg)
KV Caching: Speeding up LLM Inference [Lecture]

KV Cache in 15 min
Full Guide
Data is compiled from public records and verified media reports.
Last Updated: May 27, 2026
Final Thoughts

For 2026, The Kv Cache Memory Usage In Transformers remains one of the most talked-about profiles. Check back for the latest updates.
Disclaimer:


![KV Caching: Speeding up LLM Inference [Lecture]](https://i0.wp.com/ytimg.googleusercontent.com/vi/_quDGLpNols/mqdefault.jpg?resize=320,180)
















