Expected Attention Llm Kv Cache Compression Information Center
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.
Overview to Expected Attention Llm Kv Cache Compression

In this AI Research Roundup episode, Alex discusses the paper: ' Try Voice Writer - speak your thoughts and let AI handle the grammar: The In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the Have you ever wondered how massive language models like DeepSeek-R1 and Qwen3 handle complex math problems without ... MIT, NVIDIA, and Zhejiang University released TriAttention, achieving 50x Is the "Memory Wall" finally crumbling? In this video, we dive deep into **TurboQuant**, a revolutionary framework that addresses ...
In this AI Research Roundup episode, Alex discusses the paper: 'Kwai Summary In this AI Research Roundup episode, Alex discusses the paper: 'TriAttention: Efficient Long Reasoning with Trigonometric Long-context AI gets expensive fast, and one of the biggest reasons is Ever wondered how large language models like GPT respond so fast without recomputing everything from scratch? In this video, I ... Lex Fridman Podcast full episode: Thank you for listening ❤ our ... In this AI Research Roundup episode, Alex discusses the paper: 'OCTOPUS: Optimized
Important Facts

Explore the main sources for Expected Attention Llm Kv Cache Compression.
Latest News

Stay updated on Expected Attention Llm Kv Cache Compression's newest achievements.
Featured Video Reports & Highlights
Below is a handpicked selection of video coverage, expert reports, and highlights regarding Expected Attention Llm Kv Cache Compression from verified contributors.

Expected Attention: LLM KV Cache Compression
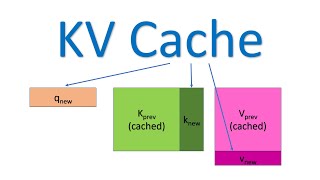
The KV Cache: Memory Usage in Transformers

KV Cache: The Trick That Makes LLMs Faster

How TriAttention Achieves 2.5x Faster LLM Reasoning (KV Cache Compression)
Expert Insights
Data is compiled from public records and verified media reports.
Last Updated: May 27, 2026
Final Thoughts

For 2026, Expected Attention Llm Kv Cache Compression remains one of the most talked-about profiles. Check back for the latest updates.
Disclaimer:



















