Kv Cache Crash Course Information Center
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.
Overview of Kv Cache Crash Course

Try Voice Writer - speak your thoughts and let AI handle the grammar: The In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the Don't miss out! Join us at our next KubeCon + CloudNativeCon events in Mumbai, India (18-19 June, 2026), Yokohama, Japan ... Ever wonder how even the largest frontier LLMs are able to respond so quickly in conversations? In this short video, Harrison Chu ... Same prompt. Same model. The first call costs $1.00. The second costs $0.05. Same words — 20× cheaper. The reason isn't a ... In this video I am explaining the one trick that makes token generation on modern LLMs 10-100 times faster: the
Ready to become a certified watsonx Generative AI Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Full explanation of the LLaMA 1 and LLaMA 2 model from Meta, including Rotary Positional Embeddings, RMS Normalization, ... Open-source LLMs are great for conversational applications, but they can be difficult to scale in production and deliver latency ... Get a Free System Design PDF with 158 pages by subscribing to our weekly newsletter.: Animation ...
Core Information

Explore the main sources for Kv Cache Crash Course.
History

Stay updated on Kv Cache Crash Course's latest milestones.
Featured Video Reports & Highlights
Below is a handpicked selection of video coverage, expert reports, and highlights regarding Kv Cache Crash Course from verified contributors.

KV Cache Crash Course
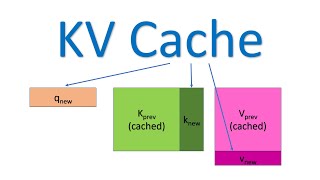
The KV Cache: Memory Usage in Transformers
![KV Caching: Speeding up LLM Inference [Lecture]](https://ytimg.googleusercontent.com/vi/_quDGLpNols/mqdefault.jpg)
KV Caching: Speeding up LLM Inference [Lecture]

KV Cache: The Trick That Makes LLMs Faster
Detailed Analysis
Data is compiled from public records and verified media reports.
Last Updated: May 27, 2026
Future Outlook

For 2026, Kv Cache Crash Course remains one of the most searched-for profiles. Check back for the newest reports.
Disclaimer:


![KV Caching: Speeding up LLM Inference [Lecture]](https://i0.wp.com/ytimg.googleusercontent.com/vi/_quDGLpNols/mqdefault.jpg?resize=320,180)
















