Oscar 2 Bit Kv Cache Quantization For Llms Information Center
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.
Overview to Oscar 2 Bit Kv Cache Quantization For Llms

In this AI Research Roundup episode, Alex discusses the paper: ' Try Voice Writer - speak your thoughts and let AI handle the grammar: The 00:00 Attention Is Geometry 00:53 TurboQuant Introduction 01:02 Two Problems with Standard In this AI Research Roundup episode, Alex discusses the paper: 'OCTOPUS: Optimized Lex Fridman Podcast full episode: Thank you for listening ❤ our ... In this video, we discuss the fundamentals of model
Is the "Memory Wall" finally crumbling? In this video, we dive deep into **TurboQuant**, a revolutionary framework that addresses ... Every time I do a video about a model I get a comment saying "Well you never said what it takes to run it!" Well since I am not ... In this AI Research Roundup episode, Alex discusses the paper: 'Not All In this AI Research Roundup episode, Alex discusses the paper: 'DualPath: Breaking the Storage Bandwidth Bottleneck in ... Same prompt. Same model. The first call costs $1.00. The second costs $0.05. Same words — 20× cheaper. The reason isn't a ...
Important Facts

Explore the key sources for Oscar 2 Bit Kv Cache Quantization For Llms.
History

Stay updated on Oscar 2 Bit Kv Cache Quantization For Llms's latest milestones.
Featured Video Reports & Highlights
Below is a handpicked selection of video coverage, expert reports, and highlights regarding Oscar 2 Bit Kv Cache Quantization For Llms from verified contributors.

OScaR: 2-Bit KV Cache Quantization for LLMs

KV Cache: The Trick That Makes LLMs Faster
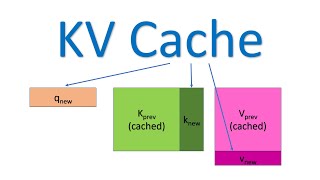
The KV Cache: Memory Usage in Transformers

TurboQuant Explained: 3-Bit KV Cache Quantization
Full Guide
Data is compiled from public records and verified media reports.
Last Updated: May 27, 2026
Final Thoughts

For 2026, Oscar 2 Bit Kv Cache Quantization For Llms remains one of the most talked-about profiles. Check back for the latest updates.
Disclaimer:


















